团队名称:极限定理
项目名称:爬取豆瓣电影Top250
组长:邵文强
成员:张晓亮、潘新宇、邵翰庆、宁培强、李国峰
总结:
一.项目效果演示:
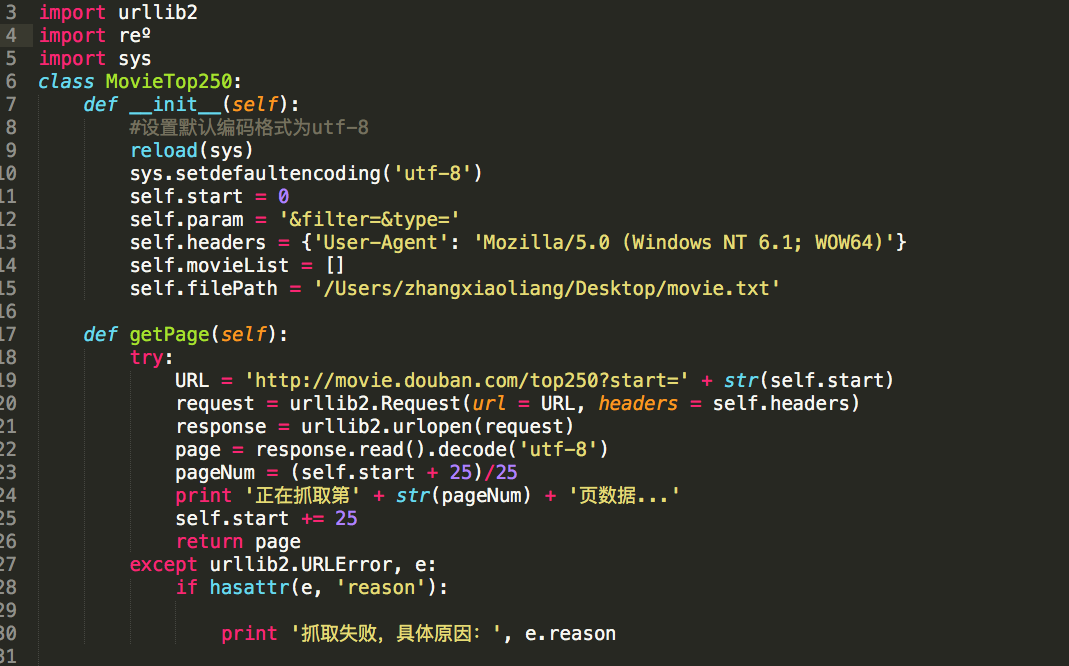
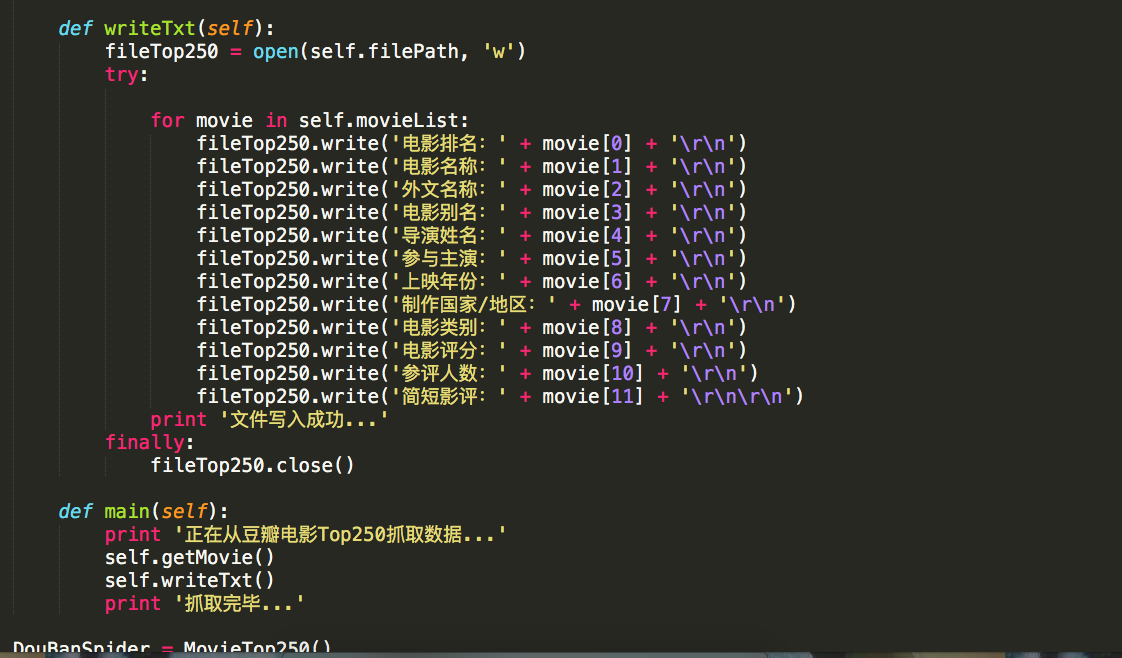
输入网址,查询页面所有信息。
针对电影类别查询,统计,整合。
二.项目的背景和相关工作:
项目的分析
项目针对的实际问题
完成项目的相关工作(需求的实际报告、程序的设计)
三.确定项目的方向-针对信息的搜索
针对网页的搜索引擎发的很比较成熟,而针对的信息的搜索正在成为热点,而且技术上更有难度。
四.项目遇到的问题:
爬虫的实时性的问题
网站对爬虫的限制
自然语言的信息提取
(信息更新不是很快)
(信息提取相对容易)
五.针对软件资源的问题:
正则表达式导致读取网页过慢。
软件资源的更新速度不算太快,我们的爬虫可以跟上更新的速度。
所有的信息是半结构化,信息的提取比自然语言提取更容易。
在实际中,有比较好的应用。
六.项目的相关的工作:
信息提取
自然语言处理
增量式爬虫的原理
半结构化的信息提取
七.分析设计:
需求分析
项目的框架
网络爬虫
半结构化信息提取
查询的预处理
功能需求分析:
1.能够下载任何http协议和HTTPS协议的链接的网页
2.构造http请求中的GET请求
3.分析http响应请求。
4.提取网页链接并统计数量。
5.保存,能够正确的保存网页及网页信息到文件。
功能模块流程图:
构造GET请求——>链接网站服务器——>发送GET请求——>接受网站的数据——>分析HTTP报文头
需要说明的问题:
1,.利用系统函数把网页读入内存。
2.利用正则表达式提取相关信息。
3.把一个网页URL写入文件保存。
八.模块
主要事件流:
1.构造GET请求
2.链接服务器。
3.发送GET请求
4.接受网站返回的数据。
异常事件:
1.申请大块内存失败。
2.分配内存对象失败。
3.链接网站服务器失败。
4.发送请求失败。
5.接受网站返回数据失败
九.基本工具的使用
1) urllib2: urllib2的基本用途、只要函数,如何post数据,cookie的设置
2)异常处理的方式:
a)try...except
b)Http异常码
3) 文件读写创建等常用操作
4)关于编码问题
5)运用以上工具实现一个基本网页的抓取。
十.测试与结果
对爬虫程序的设计:输入不合法的URL。能弹出错误提示。
输入各种类型的URL,只对http和HTTPS链接处理其他链接被视为异常。
图片示例: